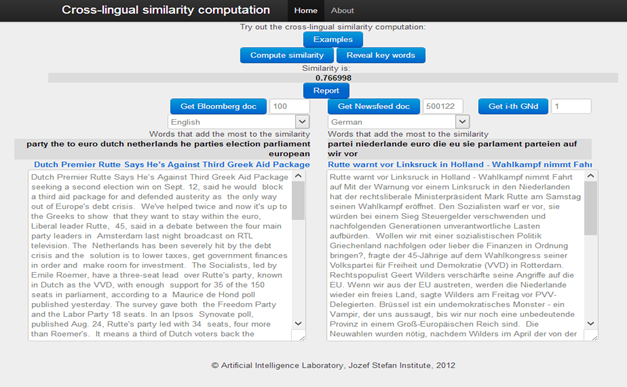
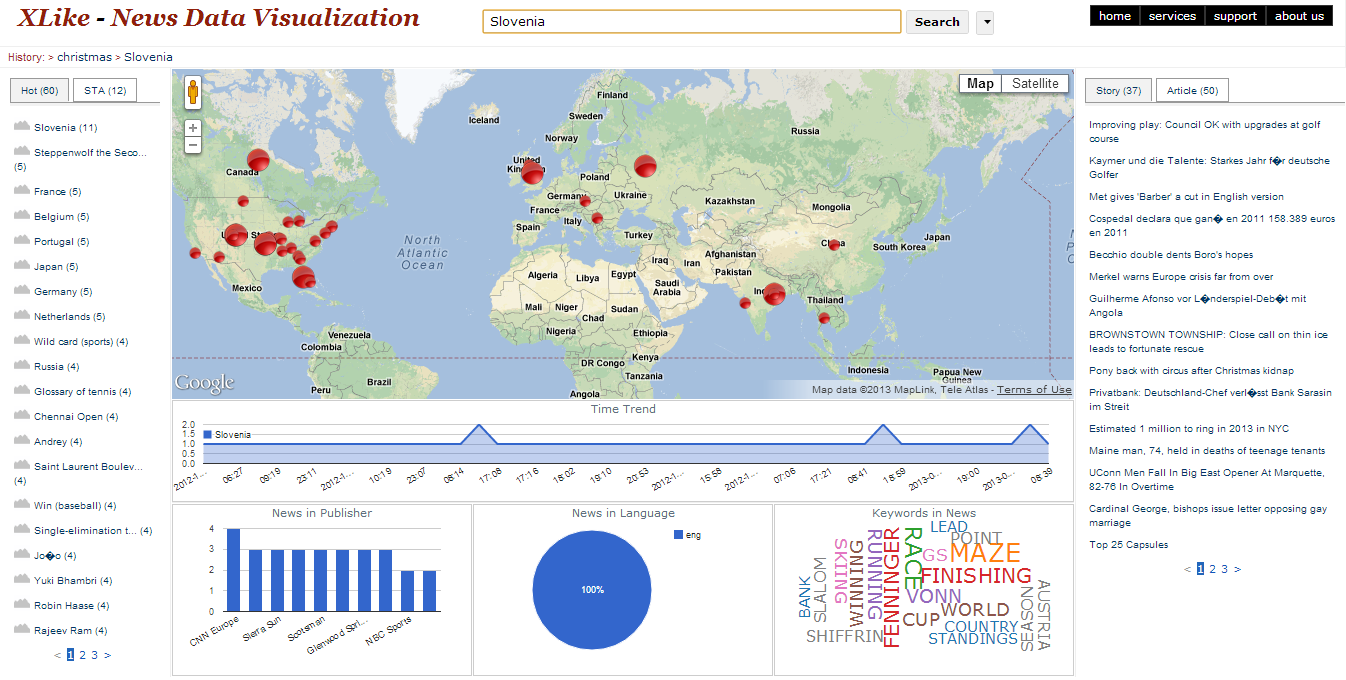
Xlike requires the linguistic processing of large numbers of documents in a variety of languages.
Thus, WP2 is devoted to building language analysis pipelines that will extract from texts the core knowledge that the project is built upon.
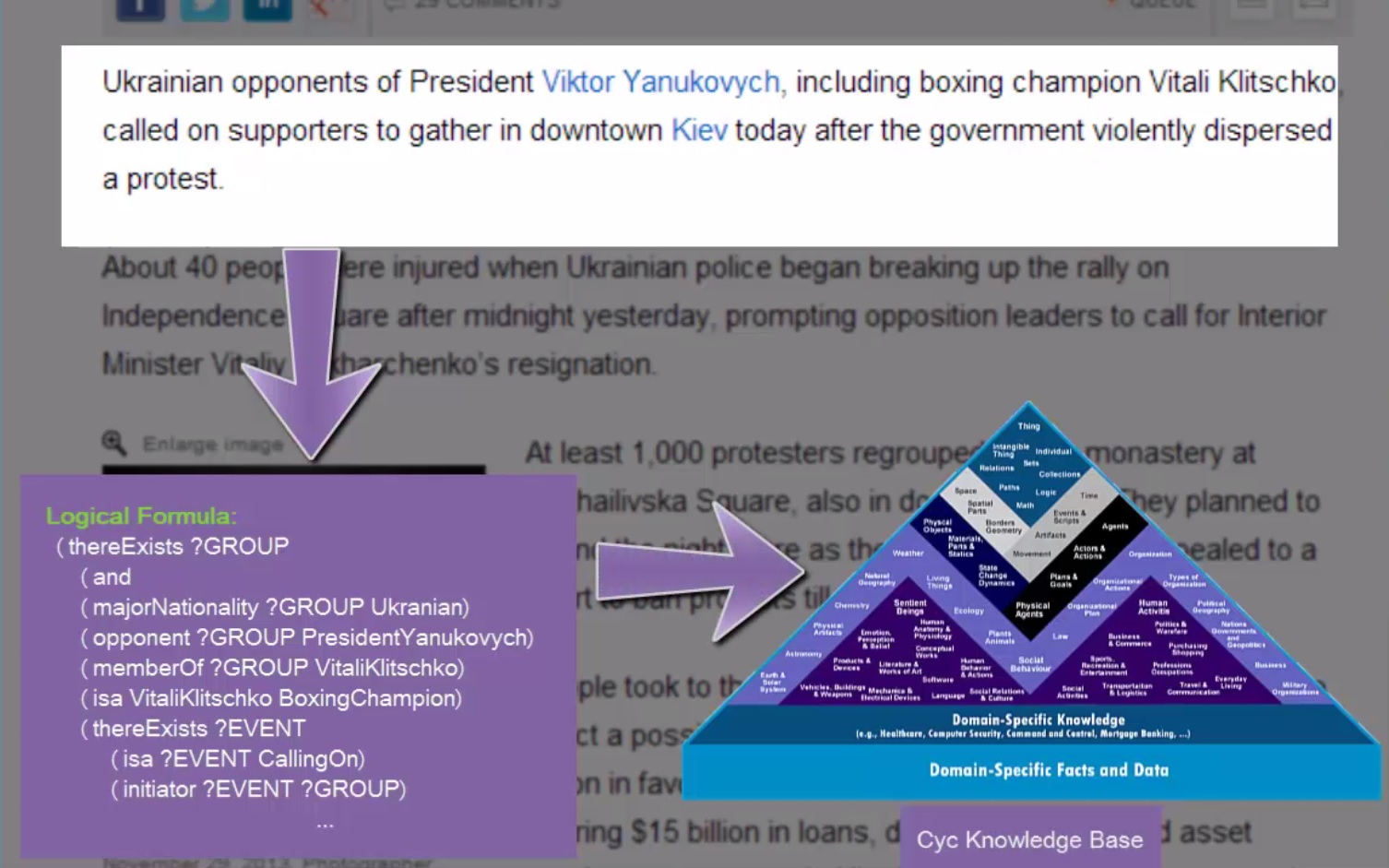
The different language functionalities are implemented following the service oriented architecture (SOA) approach defined in the project Xlike, and presented in Figure 1.
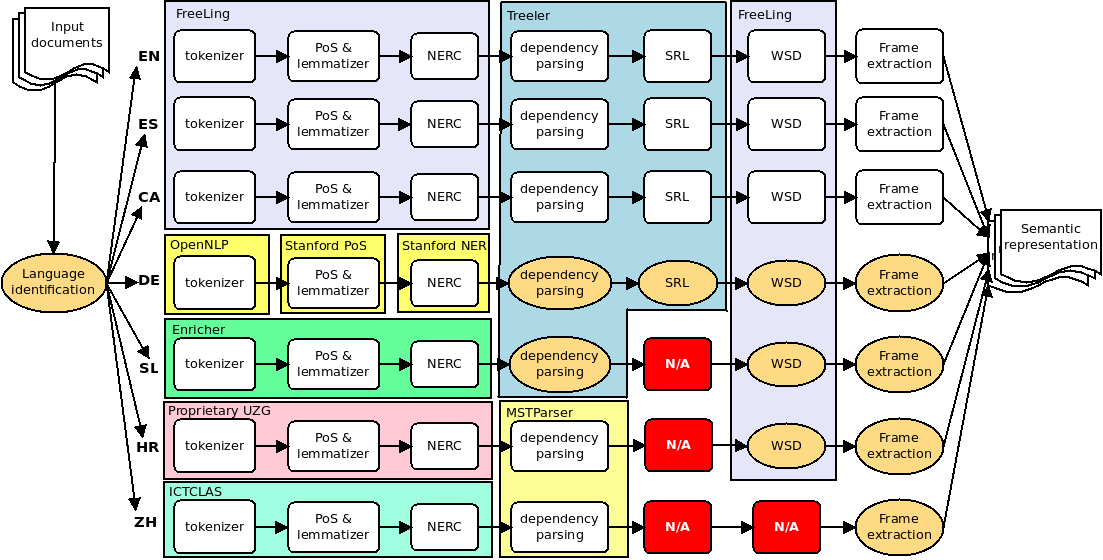 Figure 1: Xlike Language Processing Architecture.
Figure 1: Xlike Language Processing Architecture.
Therefore all the pipelines (one for each language) have been implemented as web services and may be requested to produce different levels of analysis (e.g. Tokenization, lemmatization, NERC, parsing, relation extraction, etc.). This approach is very appealing due to the fact that it allows to treat every language independently and to execute the whole language analysis process at different threads or computers allowing an easier parallelization (e.g., using external high performance platforms such as Amazon Elastic Compute Cloud EC2 as needed. Furthermore, it also provides independent development life-cycles for each language which is crucial in this type of research projects. Recall that these web services can be deployed locally or remotely, maintaining the option of using them in a stand-alone configuration.
Figure 1 also represents by large boxes the different technology used for the implementation of each module. White square modules indicates those functionalities that run locally inside a web service and can’t be accessed directly, and shaded round modules indicate private web services which can be called remotely for accessing the specified functionality.
Each language analysis service is able to process thousands of words per second when performing shallow analysis (up to NE recognition), and hundreds of words per second when producing the semantic representation based on full analysis.
For instance, the average speed for analyzing an English document with shallow analysis (tokenizer, splitter, morphological analyzer, POS tagger, lemmatization, and NE detection and classification) is about 1,300 tokens/sec on a i7 3.4 Ghz processor (including communication overhead, XML parsing, etc.). This means that an average document (e.g, a news item of around 400 tokens) is analyzed in 0.3 seconds.
When using deep analysis (i.e., adding WSD, dependency parsing, and SRL to the previous steps), the speed drops to about 70 tokens/sec, thus an average document takes about 5.8 seconds to be analyzed.
The parsing and SRL models are still in a prototype stage, and we expect to largely reduce the difference between shallow and deep analysis times.
However, it is worth noting that the web-service architecture enables the same server to run a different thread for each client without using much extra memory. This exploitation of multiprocessor capabilities allows a parallelism degree of as many request streams as available cores, yielding an actually much higher average speed when large collections must be processed.
Semantic Representation
Apart from the basic state-of-the-art tokenizers, lemmatizers, PoS/MSD taggers, and NE recognizers, each pipeline requires deeper processors able to build the target language-independent semantic representation. For that, we rely on three steps: dependency parsing, semantic role labeling and word sense disambiguation. These three processes, combined with multilingual ontological resources such as different WordNets, are the key to the construction of our semantic representation.
Dependency Parsing
In XLike, we use the so-called graph-based methods for dependency parsing. In particular we use MSTParser for Chinese and Croatian, and Treeler –a library developed by the UPC team that implements several methods for dependency parsing, among other statistical methods for tagging and parsing– for the other languages.
Semantic Role Labeling
As with syntactic parsing, we are using the Treeler library to develop machine-learning based SRL methods. In order to train models for this task, we use the treebanks made available by the CoNLL-2009 shared task, which provided data annotated with predicate-argument relations for English, Spanish, Catalan, German and Chinese. No treebank annotated with semantic roles exists for Slovene or Croatian yet, thus, no SRL module is available for these languages in XLike pipelines.
Word Sense Disambiguation
The used Word Sense Disambiguation engine is the UKB implementation provided by FreeLing. UKB is a non-supervised algorithm based on PageRank over a semantic graph such as WordNet.
Word sense disambiguation is performed for all languages for which a WordNet is publicly available. This includes all languages in the project except Chinese.
The goal of WSD is to map specific languages to a common semantic space, in this case, WN synsets. Thanks to existing connections between WN and other resources, SUMO and OpenCYC sense codes are also output when available. Finally, we use PredicateMatrix –a lexical semantics resource combining WordNet, FrameNet, PropBank, and VerbNet– to project the obtained concepts to PropBank predicates and FrameNet diathesis structures, achieving a normalization of the semantic roles produced by the SRL (which are treebank-dependent, and thus, not the same for all languages).
Frame Extraction
The final step is to convert all the gathered linguistic information into a semantic representation. Our method is based on the notion of frame: a semantic frame is a schematic representation of a situation involving various participants. In a frame, each participant plays a role. There is a direct correspondence between roles in a frame and semantic roles; namely, frames correspond to predicates, and participants correspond to the arguments of the predicate. We distinguish three types of participants: entities, words, and frames.
1 Acme acme NP B-PER 8 SBJ _ _ A1 A0 A0
2 , , Fc O 1 P _ _ _ _ _
3 based base VBN O 1 APPO 00636888-v base.01 _ _ _
4 in in IN O 3 LOC _ _ AM-LOC _ _
5 New_York new_york NP B-LOC 4 PMOD 09119277-n _ _ _ _
6 , , Fc O 1 P _ _ _ _ _
7 now now RB O 8 TMP 09119277-n _ _ AM-TMP _
8 plans plan VBZ O 0 ROOT 00704690-v plan.01 _ _ _
9 to to TO O 8 OPRD _ _ _ A1 _
10 make make VB O 9 IM 01617192-v make.01 _ _ _
11 computer computer NN O 10 OBJ 03082979-n _ _ _ A1
12 and and CC O 11 COORD _ _ _ _ _
13 electronic electronic JJ O 14 NMOD 02718497-a _ _ _ _
14 products product NNS O 12 CONJ 04007894-n _ _ _ _
15 . . Fp O 8 P _ _ _ _ _
Figure 2: Output of the analyzers for the sentence Acme, based in New York, now plans to make computer and electronic products
For example, in the sentence in Figure 2, we can find three frames:
- Base: A person or organization being established or grounded somewhere. This frame has two participants: Acme, a participant of type entity playing the theme role (the thing being based), and New York, a participant of type entity playing the role of location.
- Plan: A person or organization planning some activity. This frame has three participants: Acme, a participant of type entity playing the agent role, now, a participant of type word playing the role of time, and make, a participant of type frame playing the theme role (i.e., the activity being planned).
- Make: A person or organization creating or producing something. Participants in this frame are: Acme, entity playing the agent role, and products, a participant of type word playing the theme role (i.e., the thing being created).
A graphical representation of the example sentence is presented in Figure 3.
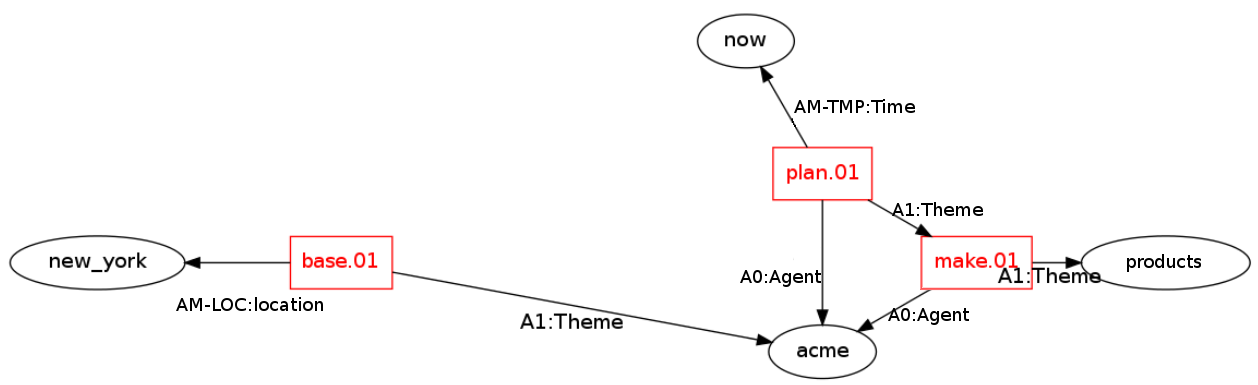
Figure 3: Graphical representation of frames in the example sentence.
It is important to note that frames are a more general representation than SVO-triples. While SVO-triples represent binary relations between two participants, frames can represent any n-ary relation. For example, the frame for plan is a ternary relation because it includes a temporal modifier. It is also important to note that frames can naturally represent higher-order relations: the theme of the frame plan is itself a frame, namely make.
Finally, although frames are extracted at sentence level, the resulting graphs are aggregated in a single semantic graph representing the whole document via a very simple co-reference resolution method based on detecting named entity aliases and repetitions of common nouns.
Future improvements include using a state-of-the-art co-reference resolution module for languages where it is available.
Source code
The code that was used to process text and generate the output shown above is available under an open-source licence and can be downloaded here.