TextToLogic system is a semi-automatic information extraction system. It allows high precision extraction of deep knowledge structures from multiple languages. By suggesting at several stages of extraction pipeline, the system minimizes the work of human annotator, which makes the extraction economically viable. The extracted knowledge is added to Cyc, which is a common sense knowledge base that allows question answering and reasoning.
The extraction process starts with selecting the language and an arbitrary document. The system is suitable for macro-reading, where the goal is to extract a collection of facts from a large collection of documents, as opposed to micro-reading, where the goal is to extract every fact from a single document. In the following steps, the user creates a pattern rule for one semantic relation.
After the document is presented to the user, he selects a fraction of text (e.g. Cevin Jones, owner of Intermountain Beef Producers) that expresses a fact and drags it into the lexical pattern box. Immediately an interface for creating lexical patterns will appear. The interface allows the user to create arguments of the pattern and their types by generalizing words of short phrases (e.g. Cevin Jones -> Person). The user can select from several NLP layers, such as part-of speech tags and named-entities, provided by XLike NLP pipeline. After the user finishes the construction, the systems inspects the lexical pattern and queries the knowledge base for concepts, which might be used in the logical pattern. Considering these suggestion and initial generic logical pattern suggestion, the user then finishes the logical pattern and consequently the pattern rule.

After the pattern rule is constructed and added to the rule repository, the system searches for all matches of the rule in all documents. The algorithm first finds all the sentences containing the tokens from the lexical pattern using indexing, then it applies a pattern matching algorithm. If there are any arguments without a type at the beginning or at the end of the pattern, then the algorithm utilizes syntactic trees (also from the XLike pipeline) to determine how many words to match. The algorithm is adding words to the match until the whole match is a connected sub-tree of the syntax tree. These matches are colored orange and the user can click on them to open the interface for adding the selected extraction to the knowledge base. For each argument the user must select the correct concept from the knowledge base (disambiguation) or create a new one.
One of the important features of the system is the ability to construct nested rules, thus creating deep knowledge structures. For instance, if we would like to extract Walter E. Williams is a professor of economics, then it is possible to make a rule for extracting concepts of professors of any field. This rule will then be nested inside the “is-a” rule. The result of the extraction is a logical formula: (isa WalterWilliams (ProfessorFn Economics)).
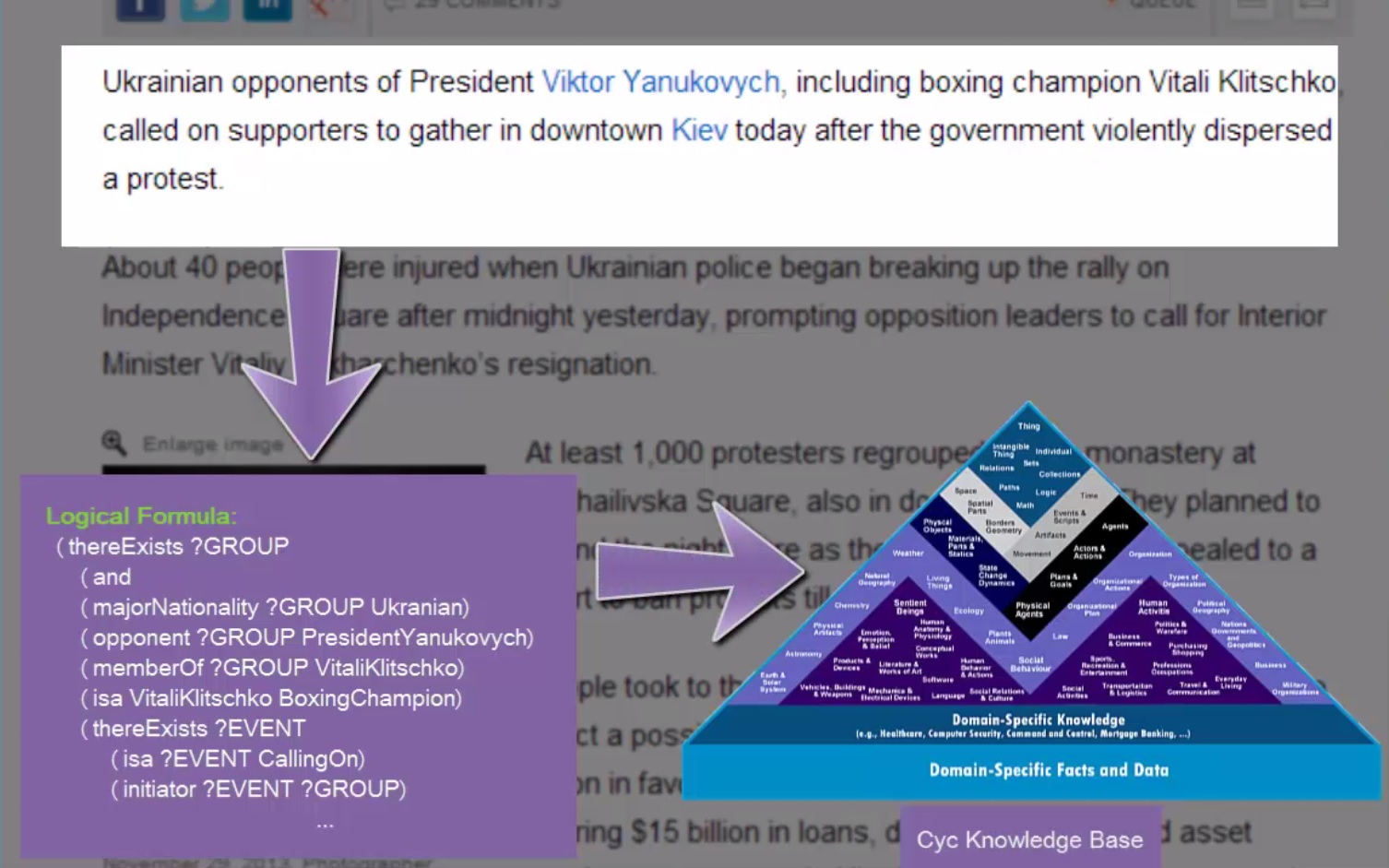
Once the knowledge is stored in knowledge, we can query it or reason about it. But more on that is presented in the video as well as the whole extraction process.

