Measuring similarity between documents written in different languages is useful for several tasks, for example when building a cross-lingual content based recommendation system. Another example is tracking how news spreads which may involve crossing different languages.
Having a cross-lingual similarity function and a common representation which is language independent enables us to transform cross-lingual text mining problems (CL-classification, CL-information retrieval, CL-clustering) to standard machine learning techniques.
Below we illustrate how to construct the language independent document representations as well as the cross-lingual similarity function, based on a multilingual document collection (training data).
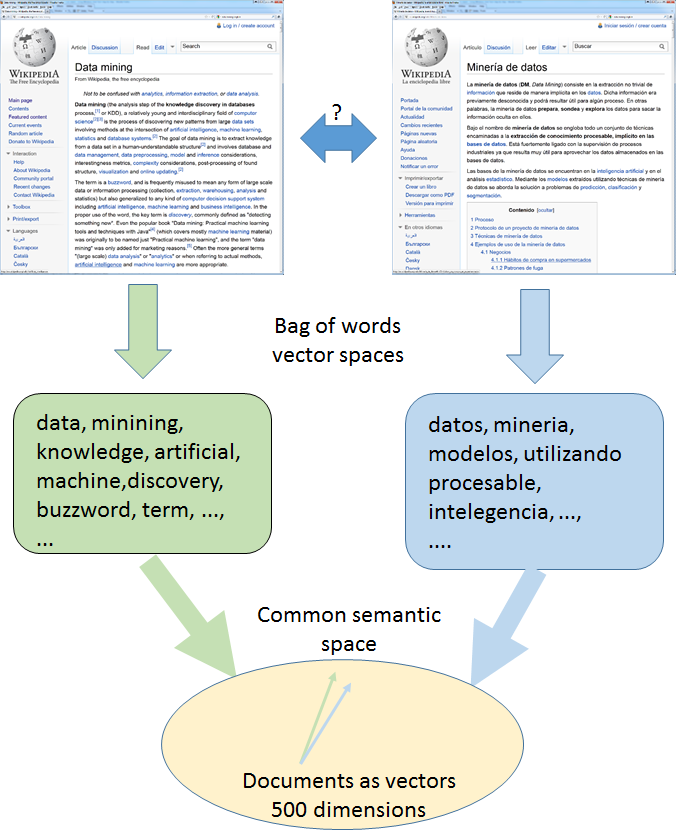
The current technology is based on LSI (latent semantic index) and CCA (canonical correlation analysis) approach described in:
- (LSI) Primoz Skraba, Jan Rupnik, and Andrej Muhic. Low-rank approximations for large, multi-lingual data. Low Rank Approximation and Sparse Representation, NIPS 2011 Workshop, 2011.B [link].
- (CCA) Cross-lingual document retrieval through hub languages. V: 2012 Workshop book : NIPS 2012, Neural Information Processing Systems Workshop, December 7-8, 2012, Lake Tahoe, Nevada, US. [S. l.]: Neural Information Processing System Foundation, 2012, 5 str. [link].
Both approaches use the Wikipedia alignment information to produce the compressed aligned topics. That enables the mapping of documents in language independent space. Data compression and multilingual topic computation in LSI case is done using SVD – singular value decomposition to reduce the noise and the complexity of similarity computation. In CCA case we first compress the covariance matrices using SVD and then refine the topics using generalized version of CCA.
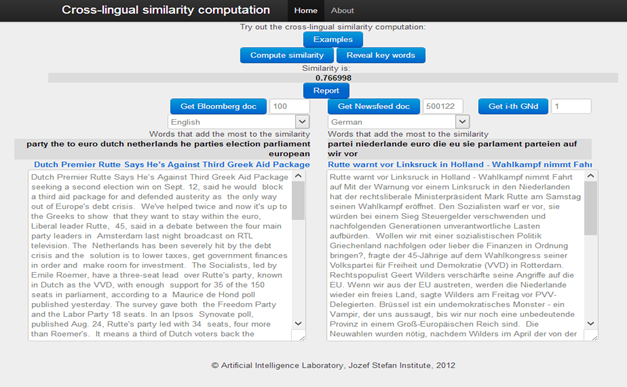
Web demo of cross-lingual similarity search

